本系列文章跳转目录如下:
- 是什么,为什么,如何使用
- 信令(交换信令消息后,WebRTC Agent才可以直接相互通信。)
- 连接( 为什么WebRTC需要专用的子系统进行连接,又是怎样连接的?)
- 安全性( WebRTC具有哪些安全性保障,又是如何做到的?)
- 搭建实时网络(网络在实时通信中的重要性以及如何处理网络中的各种问题)
- 媒体通信(WebRTC媒体通信的作用及其工作原理)
- 数据通信(WebRTC数据通信的作用及其工作原理)
- WebRTC应用场景(人们使用WebRTC构建什么以及他们是如何实现的)
- 调试(如何分析并定位相关问题,以及一些流行的调试工具)
- 历史(对WebRTC一系列协议作者的采访)
- 常见问题( 使用WebRTC时常见的问题及解答)
- 术语
我可以从WebRTC的媒体通信中得到什么?
WebRTC允许你发送和接收无限多条音频和视频流。你可以在通话期间随时添加和删除这些流。这些流可以全部独立,也可以捆绑在一起!你甚至可以将网络摄像头的音频和视频放到你桌面的视频中,然后将此视频以feed的形式发送出去。
WebRTC协议与编解码器无关。底层传输支持所有格式的内容,即使是还不存在的格式! 但是,你正与之通信的WebRTC Agent可能没有必要的工具来接受它。
WebRTC针对动态网络状况也有对应的处理方案。在通话过程中,带宽可能会增加或减少。甚至可能突然间大量丢包。该协议对所有这类问题的处理都做了相应的设计。WebRTC根据网络状况作出响应,并尝试利用可用资源为你提供最佳体验。
它是如何工作的?
WebRTC使用RFC 1889中定义的两个既有协议RTP和RTCP。
RTP(实时传输协议/Real-time Transport Protocol)是承载媒体的协议。它为视频的实时传输而设计。它没有规定有关延迟或可靠性的任何规则,但是为你提供了实现这些规则的工具。RTP提供了流的设计,因此你可以通过一个连接发布多个媒体源。它还为你提供了完善媒体传递途径所需的计时和排序信息。
RTCP(RTP控制协议/RTP Control Protocol)是用于传达有关呼叫的元数据的协议。其格式非常灵活,并允许你可以添加所需的任何元数据。这点被用来传达有关呼叫的统计信息。也是处理分组丢失和实现拥塞控制的必备特性。它为你提供了响应变化的网络状况所必需的双向通信能力。
延迟与质量
实时媒体就是要在延迟和质量之间进行权衡。你愿意忍受的延迟时间越长,可以预期的视频质量就越高。
现实世界的局限性
下面这些限制都是由现实世界的局限性引起的。它们都是你需要考虑的网络特性。
视频是复杂的
传输视频并不容易。要存储30分钟未经压缩的720p的8-bit视频,你需要大约110GB。按照这个数据,4人电话会议就开不成了。我们需要一种缩小容量的方法,而答案就是视频压缩。但是,这并非没有缺点。
视频101
我们不会深入介绍视频压缩,只需要让大家足以理解为什么RTP是这么设计的。视频压缩会将视频编码为一种新格式,这样可以需要较少的bit数来表示同一视频。
有损和无损压缩
你可以将视频编码为无损(无信息丢失)或有损(信息可能丢失)压缩。由于无损编码需要将更多的数据发送到对端,这样会导致更高的流延迟和更多的丢包,因此RTP通常使用有损压缩,即使这样可能会导致视频质量不佳。
帧内和帧间压缩
视频压缩有两种类型。首先是帧内压缩。帧内压缩减少了用于描述单个视频帧的bit数。相同的技术被用来压缩静态图片,例如JPEG压缩方法。
第二种类型是帧间压缩。由于视频是由许多图片组成的,因此我们需要寻找无需将相同信息发送两次的方式。
帧间压缩
帧有三种类型:
- I帧 - 一张完整的图片,无需任何其他内容即可解码。
- P帧 - 一张图片的一部分,仅包含对之前图片的修改。
- B帧 - 一张图片的一部分,包含对之前图片和将来图片的修改。
以下是对这三种类型帧的图解。

视频很脆弱
压缩后的视频是有状态的,(视频解码)非常依赖其上下文,这使得视频很难通过Internet进行传输。想像一下,如果I帧的一部分丢失了会怎样?这样P帧如何知道要修改的内容? 随着视频压缩变得越来越复杂,这成为一个更大的问题。幸运的是,RTP和RTCP对此都有解决方案。
RTP
Packet Format(包格式)
每个RTP数据包都具有以下结构:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|V=2|P|X| CC |M| PT | Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Timestamp |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Synchronization Source (SSRC) identifier |
+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+
| Contributing Source (CSRC) identifiers |
| .... |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Version (V)
Version总是2。
Padding (P)
Padding是控制有效载荷是否具有填充值的布尔值。
有效负载的最后一个字节包含添加了多少填充字节的计数。
Extension (X)
如果设置的话,RTP报头将有扩展段(可选)。这点将在下面更详细地描述。
CSRC count (CC)
在SSRC之后,有效负载之前的CSRC标识符的数量。
Marker (M)
标记位没有预设含义,用户可以根据自己的需求随意使用它。
在某些情况下,它是在用户讲话时设置的。它还通常用于标记关键帧。
Payload Type (PT)
Payload Type(负载类型)是此数据包所承载的编解码器的一个唯一标识符。
对于WebRTC,Payload Type是动态的。一个呼叫中的VP8的PT可能与另一个呼叫中的不同。呼叫中的offerer确定Payload Type到Session Description(会话描述符)中的编解码器的映射。
Sequence Number
Sequence Number(序列号)用于对流中的数据包进行排序。每次发送数据包时,Sequence Number都会增加1。
RTP被设计为可以在有损网络上使用。这为接收器提供了一种检测数据包何时丢失的方法。
Timestamp
此数据包的采样时刻。这不是全局时钟,而是在当前媒体流中所经过的时间。举例来说,如果多个 RTP 包都属于同一视频帧,那么它们可能具有相同的时间戳。
Synchronization Source (SSRC)
SSRC是此流的唯一标识符。这使你可以在单个RTP流上传输多个媒体流。
Contributing Source (CSRC)
一个列表,用于表示哪些SSRC参与到了这个数据包中。
这通常用于语音指示器。假设在服务器端,你将多个音频源组合到一个单独的RTP流中。然后,你可以在此字段中表示"输入流A和C此时正在讲话"。
Payload
实际有效负载数据。如果设置了填充(padding)标记,则可能以添加的填充字节数结尾。
Extensions(扩展)
RTCP
Packet Format
每个RTCP数据包都具有以下结构:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|V=2|P| RC | PT | length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Version (V)
Version总是2。
Padding (P)
Padding是控制有效载荷是否具有填充值的布尔值。
有效负载的最后一个字节包含添加了多少填充字节的计数。
Reception Report Count (RC)
此数据包中的报告数。单个RTCP数据包可以包含多个事件。
Packet Type (PT)
指示RTCP数据包类型的唯一标识符。WebRTC Agent不需要支持所有这些类型,并且Agent之间的支持能力可以是不同的。下面这些是你可能经常看到的类型:
-
192- 完整的帧内请求(FIR)- -
193- 否定确认(NACK) -
200- 发送方报告 -
201- 接收方报告 -
205- 通用RTP反馈 -
206- 有效负载特定反馈
这些分组类型的意义将在下面更详细地描述。
完整的帧内请求(FIR)和图片丢失指示(PLI)
FIR和PLI消息的目的是类似的。这些消息都是向发送方请求一个完整的关键帧。PLI用于解码器得到了部分帧,但却无法解码的情况。之所以会发生这种情况,是因为你有很多数据包丢失,或者解码器崩溃了。
根据RFC 5104,当数据包或帧丢失时,不应使用FIR,那是PLI的任务。用FIR请求关键帧适用于丢包以外的其他原因(例如,当新成员进入视频会议时)。他们需要一个完整的关键帧才能开始对视频流进行解码,解码器将丢弃一些帧,直到关键帧到达为止。
对于接收方来说,在连接建立后立即请求一个完整的关键帧是个好主意,这可以最大程度地减少连接建立和在用户屏幕上显示图像之间的延迟。
PLI数据包是"有效负载特定反馈"消息的组成部分。
在实践中,能够同时处理PLI和FIR数据包的软件在两种场景下的行为是相同的。它会向编码器发送信号以产生新的完整关键帧。
Negative ACKnowledgements(否定确认)
NACK请求发送方重新发送单个RTP数据包。这通常是由于RTP数据包丢失而引起的,但是也可能由于延迟而发生。
与请求重新发送整个帧相比,NACK的带宽使用效率要高得多。由于RTP将数据包分解成很小的块,因此你实际上只是在请求丢失的一个很小的部分。接收方使用SSRC和序列号制作RTCP消息。如果发送方没有可用于重新发送的RTP数据包,那么它只会忽略该消息。
Sender and Receiver Reports(发送方和接收方报告)
这些报告用于在Agent之间发送统计信息。它传达了实际接收到的和抖动的数据包数量。
这些报告可用于诊断以及控制拥塞。
RTP/RTCP是如何协作解决问题的
RTP和RTCP需要协同解决网络引起的所有问题。这些技术仍在不断进化中!
Forward Error Correction(前向纠错)
简称为FEC。处理丢包的另一种方法。FEC指的是发送方多次重复发送相同的数据,甚至是在接收方没有要求的情况下发送。这是在RTP协议层级完成的,甚至也可以在编解码器以下的层级完成。
在呼叫的数据丢包率比较稳定的情况下,作为延迟处理方案,FEC比NACK好的多。对于NACK,必须先请求,然后重新传输丢失的数据包,数据往返的时间对性能的影响可能是很明显的。
自适应比特率和带宽估计
正如搭建实时网络章节中讨论的那样,网络是不可预测且不可靠的。带宽的可用性在整个会话中可能会多次变化。在一秒钟之内看到可用的带宽急剧变化(差别达到数量级),这样的情况并不少见。
这里的主要思路是根据预测的,当前的和将来的可用网络带宽来调整编码比特率。这样可以确保传输质量最佳的视频和音频信号,并且不会因为网络拥塞而断开连接。对网络行为建模并尝试对其进行预测的启发式方法称为带宽估计。
这里有很多细微的差别,因此,让我们来探索一下更多细节。
传递网络状态
实施拥塞控制的第一个路障是UDP和RTP不会传递网络状态。作为发送方,我不知道我的数据包在什么时候到达,甚至根本不知道它们到达了没有!
针对此问题,RTP/RTCP有三种不同的解决方案。每种都有自己的优点和缺点。使用什么方案取决于你面向的客户类型、使用的网络拓扑类型、甚至是你有多少开发时间。
接收方报告
接收方报告是一些RTCP消息,这是传递网络状态的最原始的方法。你可以在RFC 3550中找到它们。按照时间计划,它们会被发送给每个SSRC,并包含以下字段:
- 丢包率 - 自上次接收者报告以来丢失了数据包的百分比。
- 累计丢包数 - 在整个通话过程中丢了多少包。
- 接收到的最高序列号扩展 - 接收到的最后一个序列号,以及它滚动的次数。
- 到达间隔抖动(Interarrival Jitter) - 整个通话过程中的抖动滚动。(译注:RTP数据包到达时间的统计方差的估计值,以时间戳为单位进行度量,并表示为无符号整数。)
- 上次发送方报告时间戳(Last Sender Report Timestamp) - 已知的最后一次的发送方报告的时间戳,用于往返时间的计算。
发送方和接收方报告(SR和RR)配合,可以计算往返时间。
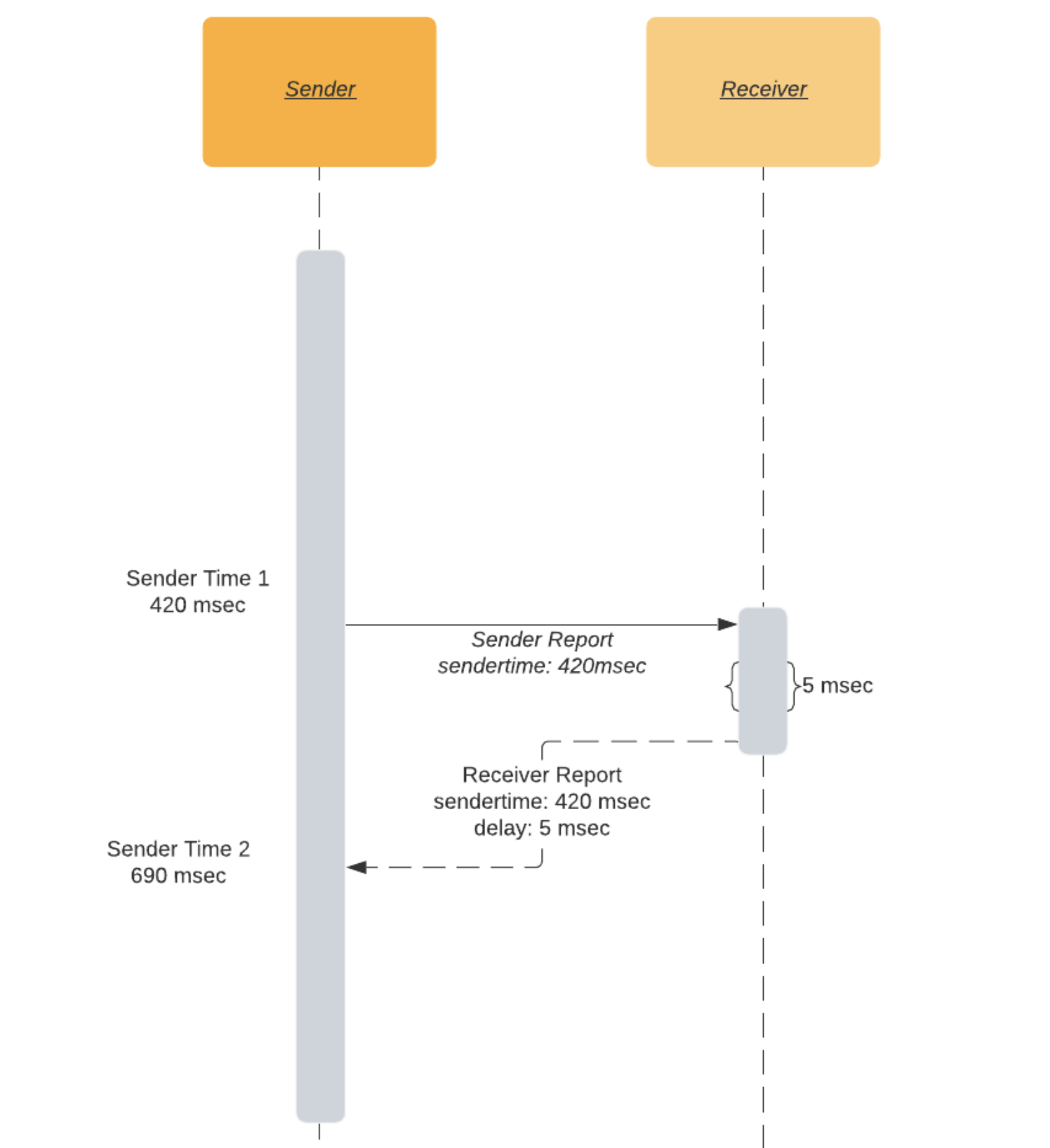
发送方在SR中包含其本地时间sendertime1。当接收方获得SR数据包时,发回RR。除了其他一些信息,RR还要包括刚从发送方接收到的sendertime1。在接收SR和发送RR之间,会有一个延迟。因此,RR还包括"自上次发送方报告以来的延迟"时间 - DLSR(delay since last sender report)。DLSR用于在该过程的稍后阶段调整往返时间的估计。一旦发送者接收到RR,它就从当前时间sendertime2中减去sendertime1和DLSR。该时间差称为往返传播延迟或往返时间。
rtt(往返时间) = sendertime2 - sendertime1 - DLSR
换个简单的说法来解释,就是这样:
- 我看了看表,向你发送了一条消息,说这是下午4点20分42秒420毫秒。
- 你再将相同的时间戳发回给我。
- (返回的消息中)还包括了从阅读我的消息到发回消息所花费的时间,例如5毫秒。
- 收到时间后,我会再次看时钟。
- 现在我的表是下午4点20分42秒690毫秒。
- 这意味着消息需要265毫秒(690-420-5)才能到达你,并返回到我。
- 因此,往返时间为265毫秒。
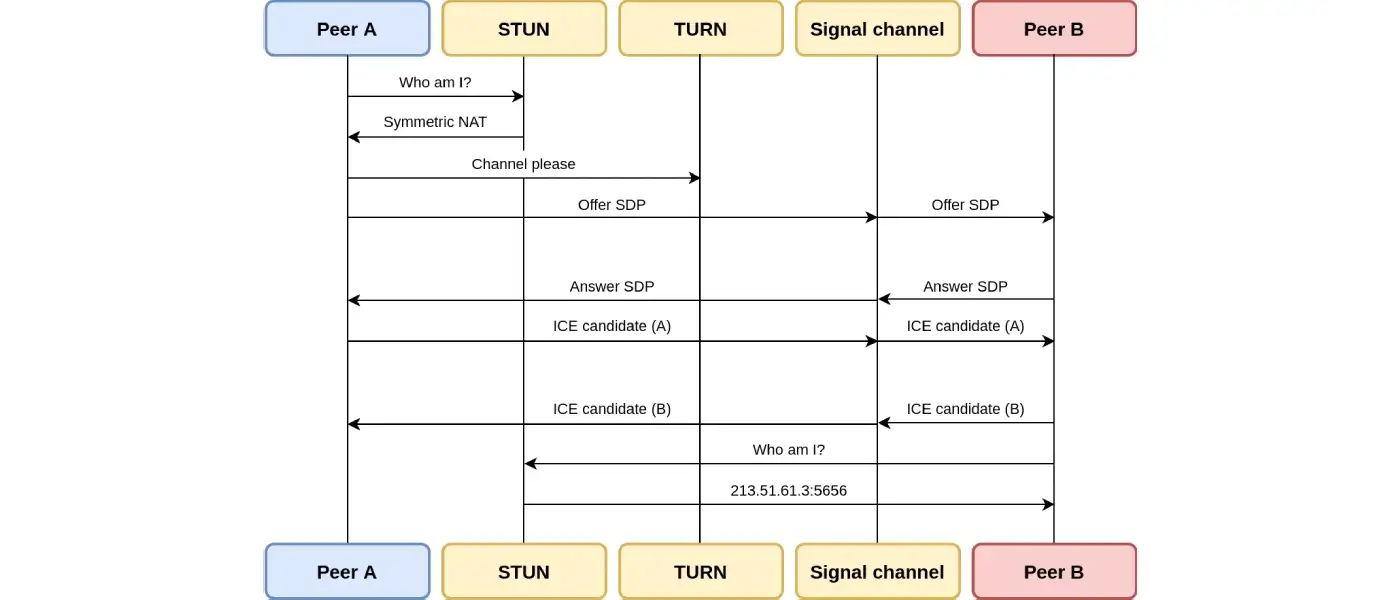
TMMBR,TMMBN和REMB
下一代的网络状态消息都是接收方通过带有显式比特率请求的RTCP消息传递给发送方。
- TMMBR(临时最大媒体码率请求) - 单个SSRC请求码率的尾数/指数。(译注:接收端当前带宽受限,告诉发送端控制码率。)
- TMMBN(临时最大媒体码率通知) - (发送端)通知(接收端)已经收到TMMBR的消息。
- REMB(接收方估计的最大码率) - 整个会话中请求码率的尾数/指数。
TMMBR和TMMBN是先出现的,它们在RFC 5104中定义。REMB是后来出现的,是在draft-alvestrand-rmcat-remb中提交的一个草案,但从未被标准化。
使用REMB的会话如下图所示:

浏览器使用简单的经验法则来估计传入带宽:
- 如果当前丢包小于2%,则告知编码器去提高比特率。
- 如果丢包高于10%,则降低比特率,减少的值为当前丢包率的一半。
if (packetLoss < 2%) video_bitrate *= 1.08
if (packetLoss > 10%) video_bitrate *= (1 - 0.5*lossRate)
这个方法在纸面上看起来效果很好。发送方从接收方接收估计值,然后将编码器比特率设置为接收到的值。啊哈!我们已经根据网络条件作出了调节。
然而,在实践中,REMB方法有几个缺点。
其中一个缺点是编码器的能力限制。当你为编码器设置比特率时,它不一定能准确的按照你要求的比特率进行输出。根据编码器的设置和正在被编码的帧的情况,它的输出可能会更少或更多。
举例来说,x264编码器,配置为tune=zerolatency,跟指定的目标比特率相比,其输出可能会产生明显的偏离。下面是一种可能的场景:
- 假设我们一开始将比特率设置为1000kbps。
- 由于没有很多高频特征值需要编码,编码器只能输出700kbps。(亦称为:“凝视一堵墙”。)
- 我们再假设接收方获得了700kbps的视频,没有发生数据包丢失,然后它将应用REMB的规则1,把输入比特率提升8%。
- 接收方向发送方发送了一个REMB包,建议将输入比特率提高到756kbps(700kbps * 1.08)。
- 发送方将编码器的比特率设置为756kbps。
- 编码器输出更低的比特率。
- 这个过程会继续重复进行,这样,比特率会被降低到绝对最小值。
你可以看到,这会导致多次编码器参数调整;同时用户会惊讶的发现,虽然连接状况良好,但视频质量看起来却让人难以接受。
传输范围内的拥塞控制(TWCC)
传输范围内的拥塞控制是RTCP网络状态通信技术的最新进展。
TWCC使用一个非常简单的原则:
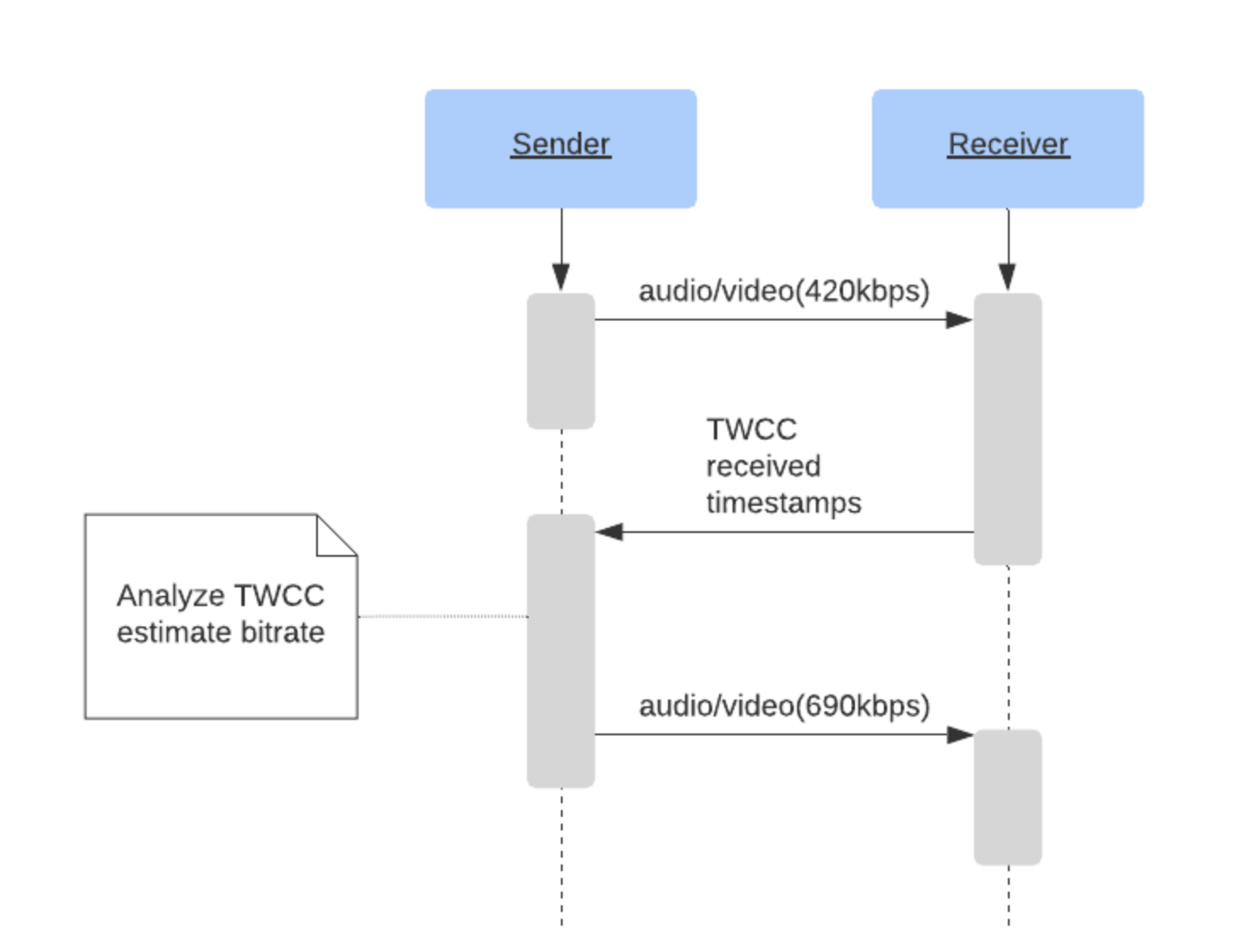
与REMB不同,TWCC的接收方不会尝试估计自己的传入比特率。它只是让发送方知道哪些包被收到了,是在什么时间收到的。基于这些报告,发送方可以了解网络的最新的状况。
- 发送方创建带有特殊的TWCC标头扩展的RTP数据包,其中包含一个数据包序列号的列表。
- 接收方以特殊的RTCP反馈消息进行响应,以使发送方知道每个数据包是否以及何时被接收。
发送方跟踪已发送的数据包,包括它们的序列号,大小和时间戳。当发送方从接收方收到RTCP消息时,它将发送数据包间的延迟与接收延迟进行比较。如果接收延迟增加,则意味着网络正在发生拥塞,发送者必须对此采取行动。
在下图中,数据包间延迟的中位数增长了+20毫秒,这清楚地表明网络正在发生拥塞。
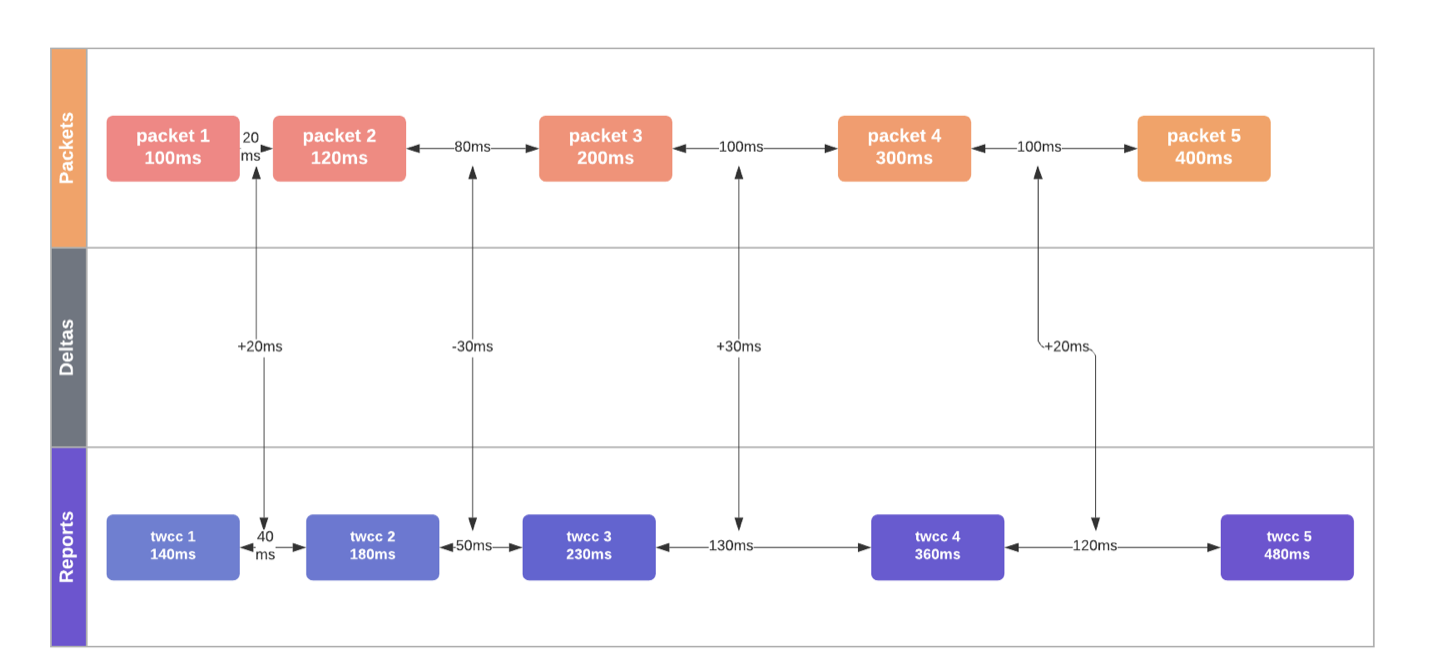
TWCC提供了原始数据和实时网络状况的绝佳视图:
- 几乎是即时的丢包统计信息,不仅包括丢失的百分比,还包括丢失的确切数据包。
- 准确的发送比特率。
- 准确的接收比特率。
- 抖动估计。
- 发送和接收数据包延迟之间的差异。
一种简单的,用于估计从发送方到接收方的传输比特率的拥塞控制算法是,将接收到的数据包大小相加,然后将其除以接收方一端经过的时间。
生成带宽估计值
现在,我们掌握了有关网络状态的信息,可以针对可用带宽进行估算了。IETF在2012年成立了RMCAT(RTP媒体拥塞避免技术)工作组。该工作组包含了已提交的多个拥塞控制算法的标准。在此之前,所有的拥塞控制算法都是专有的。
部署最多的实现是"用于实时通信的Google拥塞控制算法(GCC)",定义于draft-alvestrand-rmcat-congestion。它可以分两次运行。第一次运行是"基于损失"的,仅使用接收方报告。如果TWCC是可用的,其数据也将纳入估计。它通过使用Kalman过滤器预测当前和将来的网络带宽。
还有几种GCC的替代品,例如:NADA:一种实时媒体的统一拥塞控制方案 和 SCReAM- 多媒体的自时钟速率自适应。